
TeachMeIDEA
Learn Flutter Dart React Native JavaScript DevOps AI Backend AI Coding Tools & IDEs with practical tutorials


DeepEval LLM Evaluation: 50+ Metrics for Production Apps
If you ship an LLM feature and your only quality check is reading a handful of outputs before deploy, you...

Self-Hosting Langfuse: LLM Observability on Your Own Infra
If your LLM application handles customer records, medical notes, or internal source code, sending every prompt and completion to a...
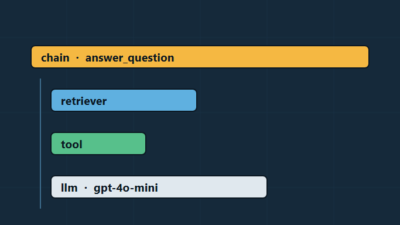
LangSmith Tracing: Debug LLM Apps End-to-End in Production
If you have ever stared at a wrong answer from your RAG pipeline and had no idea which of the...
Prompt Injection Defense: Patterns That Actually Work
Prompt injection defense is not optional once your LLM agent reads email, browses web pages, queries a document store, or...
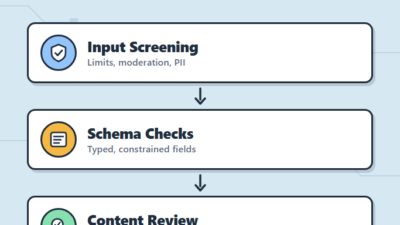
Guardrails for LLMs: Input and Output Validation Patterns
If you have shipped an LLM feature to real users, you already know the uncomfortable part: the model is the...
Structured LLM Outputs With Instructor and Pydantic Models
If you have ever wrapped an LLM call in a try/except json.JSONDecodeError and hoped for the best, this guide is for you....

LLM Rate Limiting and Retry Strategies in Production
If your app calls OpenAI, Anthropic, or any hosted model, you will eventually hit a 429 Too Many Requests. It happens...

Semantic Caching for LLMs: Cut Repeat Inference Cost
If your product sends a stream of nearly identical questions to an LLM, you are paying full price for answers...

Token Counting and Budget Management for LLM Apps
If you ship an app that calls GPT, Claude, or any other large language model, your bill is measured in...